Proteins can be structural or functional.
Proteins form parts of all cells. They also perform important biochemical functions, working as enzymes, hormones and other chemical messengers, and components of blood.
Like other biological chemicals in this section, proteins are polymers, built up from simpler monomers by condensation reactions.
Amino acids
Amino acids are the monomers from which proteins are constructed. Twenty types are found in most organisms.
Amino acids have a basic structure.

-NH
2 (also written H
2N-) is an amino group, and -COOH is a carboxylic acid (also known as a carboxyl group) - the same as in fatty acids.
Most of the variation between amino acids is due to different organic side groups, labelled above as -R.
Six different amino acids

Some R groups are quite large, and may contain groups which interact with others, by ionic interactions, forming hydrophobic or hydrophilic regions and even covalent bonding.
These groups are all attached to a carbon atom (the alpha-carbon α-C) which has a hydrogen atom attached.
Condensation reaction between two amino acids


Amino acids can undergo condensation reactions, losing -H from the amino group and -OH from the carboxylic acid group to form water.
As a result a
peptide bond (-CONH-) is formed between each amino acid residue.
Joining two amino acids in this way produces a
dipeptide.
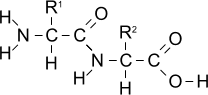
Similarly, joining three amino acids produces a tripeptide, four gives a tetrapeptide, and so on.
There are several examples of these
oligopeptides having functions in the body as hormones, etc.
Continuing the condensation process many times results in a
polypeptide.

A polypeptide chain can then become at least partly coiled or folded and then perhaps further modified to take on a particular shape which is stabilised by various bonds and attractions between the different R groups.

As a result of this folding and bonding, a polypeptide chain becomes transformed into a protein.
Some proteins consist of more than one one polypeptide chain.
Different protein molecules have different (3-dimensional) shapes according to their functions: structural proteins are mostly linear, and functional proteins are mainly globular in shape.
However it would be wrong to think that proteins have very rigid fixed shapes. For example, enzymes mould themselves around their substrates, and haemoglobin changes shape slightly as it absorbs oxygen.
Levels of protein structure
There are said to be four levels of protein structure, and each is maintained by by different types of bonds between amino acid residues.
Level:
|
Maintained by |
Primary:
Sequence of amino acid residues in polypeptide |
peptide bonds between amino acid residues |
Secondary:
(Fairly regular) coiling and folding of polypeptide chain
e.g. into alpha helix, beta sheet |
hydrogen bonds within polypeptide chain (between >C=O and HN<) |
Tertiary:
Further folding of helices/sheets to give distinctive 3-D shape |
hydrogen bonds between R groups
acid/base or hydrophobic/ hydrophilic interactions between R groups
disulphide bonds between cysteine residues
other covalent bonds
|
Quaternary
(not in all proteins):
Association of two or more polypeptide chains |
hydrogen bonds and other usually non-covalent bonds between polypeptide chains |
Plant proteins
Green plants produce proteins. In the ecological context, the term
producer is used to describe the role of plants within food webs and ecosystems. It is normally stressed that plants produce sugars as a result of photosynthesis, and that the energy in the bonds of organic compounds derived from these sugars is passed from producers to consumers.
However it is not emphasised enough that only plants can combine the element
nitrogen from inorganic sources (mostly nitrate NO
3-) in the soil with
carbon, hydrogen and oxygen contained in carbohydrates to produce
amino-acids, the building blocks of proteins.
All animal protein effectively comes from plant protein.
Plant material is often seen as having a low protein content compared with animal material. In the living world there is obviously a lot of plant protein, but it is widely spread - in effect diluted. The most abundant protein on the planet is RUBISCO - ribulose bisphosphate carboxylase, which is the key enzyme in photosynthesis.
The main sources of plant protein are (seeds of) legumes (soya and other beans, peas and other pulses) and cereals (grains). These seeds contain protein bodies, and when they germinate they produce protease enzymes which break down the insoluble protein into soluble amino acids which can be taken to the tips of roots and shoots to support growth.
There are several categories of plant proteins, some named according to the plant groups in which they are principally found.
Plant albumins include leguminins and vicilins in legumes and pulses.
Other types include globulins, and gliadins and glutelins which are protein types found mainly in cereal grains, especially wheat. Some people are allergic to these compounds, collectively known as gluten. The linear nature of these molecules can be seen when dough is made for breadmaking, and pasta.
Animal proteins
In studying the functioning of the body, it is normal to consider anatomy (details of bodily structure) in relation to physiology (how the body functions at the chemical level).
In a similar way, the main uses for protein can be said to be either structural or functional.
Structural proteins
Most structural proteins have a fibrous shape or texture at the molecular level.
These actually make up parts of the body, and reinforce tissues to increase rigidity, or generate mechanical forces for movement.
Examples
keratin
This is found within the skin, forming a waterproof layer. It is also found in distinctive structures which grow out from it to cover the body: mammals have fibres known as hair, fur or wool, birds have feathers and reptiles have scales.
Other structures such as claws, nails, hooves, horns, beaks are also made of keratin.
collagen and elastin
These form an intercellular matrix in several types of connective tissue
actin and myosin
These are the proteins responsible for muscle contraction, so they are a main component of meat
Functional proteins
Functional proteins usually have a globular shape at the molecular level, and details within the shape have a connection with the way they perform their function.
These perform a more active role in body processes.
Example categories
enzymes
e.g
carbohydrases,
proteases, lipase (digestive enzymes)
restriction endonuclease and ligase (DNA cut and paste enzymes)
(some) hormones and their receptors
e.g. insulin (and insulin receptor)
antibodies
e.g. immunoglobulins.
Each type of cell has molecules on its surface that identify
it, including proteins that act as antigens, enabling the immune
system to identify and interact with pathogens, abnormal body cells
transport proteins
e.g. haemoglobin. Possibly serum albumin could be included here.
membrane channels
e.g. carrier proteins and channel proteins involved in facilitated diffusion,
ion channel proteins: voltage sensitive Na
+ and K
+ gates, stretch-mediated Na
+ gates
pumping molecules
e.g. carrier proteins using energy from the hydrolysis of ATP in active transport
Na
+/K
+ pumps in nerve cell membranes,
food storage
Milk contains many proteins, the main one being casein, which is digested and absorbed by baby mammals, although it is converted into dairy products especially cheeses.
Ovalbumin (egg white) is the main protein in birds' eggs, providing nourishment for the developing embryo (and human consumers).
Viral proteins
In a viral infection, proteins are produced inside the host cell using the host's protein synthesis mechanisms (ribosomes etc) but
these are coded by viral nucleic acid (DNA or RNA).
Some proteins are needed for the replication cycle of the virus and to act against defence mechanisms.
Other proteins form the outer coat - also known as the capsid - of virus particles which are produced as part of the process.
These usually form geometric shapes consisting of only a few types of subunits which assemble themselves spontaneously. There may also be so called attachment proteins which latch on to molecules on the surface of host cells and enable infection to occur again.
Similarities and differences between amino acids
Most proteins are built up from combinations of about 20 ('proteinogenic') amino acids .
 Most amino acids have names ending '-ine'.
Most amino acids have names ending '-ine'.
Click the links below to see structural formulae.
Each amino acid has a three letter code, and a single letter code.
Click here to see things differently
Amino acids arranged by functional groups :
Aliphatic:
glycine
alanine
valine
leucine
isoleucine
Hydroxyl:
serine
threonine
Basic:
lysine
arginine
histidine
Aromatic:
phenylalanine
tyrosine
tryptophan
Sulphur containing:
cysteine
methionine
Acidic:
aspartic acid
glutamic acid
Amide:
asparagine
glutamine
Imino acid:
proline
Amino acids in alphabetical order:
alanine
arginine
asparagine
aspartic acid
cysteine
glutamic acid
glutamine
glycine
histidine
isoleucine
leucine
lysine
methionine
phenylalanine
proline
serine
threonine
tryptophan
tyrosine
valine
Generalised diagram
More abstruse stuff:
Zwitterion . . .
CORN rule for L and D forms
Essential amino acids
Nine of the twenty amino acids found in proteins are considered essential in the human diet
as they cannot be
made in the cells of the body:
Leucine, lysine, valine, isoleucine, phenylalanine, threonine, methionine, histidine, tryptophan.
These must therefore come from the diet.
Other amino acids can be made by conversion from these.
Other amino acids may be considered important in the diet in some circumstances.
Premature infants and those with challenging metabolic conditions may require more than the nine above.
People with the genetic condition
phenylketonuria lack the enzyme phenylalanine hydroxylase and so cannot convert phenylalanine to tyrosine, and from birth they need a modified (low protein) diet, including supplemental tyrosine.
Primary structure of proteins
This is the order or sequence of amino acid residues joined by peptide bonds in the polypeptide chain. Peptide bonds are quite strong covalent bonds.
At one end ("N-terminal") there is an unreacted amino group, and similarly there is a free carboxylic acid group at the other end ("C-terminal"), although depending on the surrounding pH these may be converted into NH
3+ or COO
-.
This sequence is always numbered starting from the N-terminal end.
For example: consider the
protein Human Chorionic Gonadotrophin (hCG) :
Click to
show/ hide the primary structure as a list of alpha chain residues:
[N terminal] ALA PRO ASP THR GLN ASP CYS PRO GLU CYS THR LEU GLN GLU ASN PRO PHE PHE SER GLN PRO GLY ALA PRO ILE LEU GLN CYS MET GLY CYS CYS PHE SER ARG ALA TYR PRO THR PRO LEU ARG SER LYS LYS THR MET LEU VAL GLN LYS ASN VAL THR SER GLU SER THR CYS CYS VAL ALA LYS SER TYR ASN ARG VAL THR VAL MET GLY GLY PHE LYS VAL GLU ASN HIS THR ALA CYS HIS CYS SER THR CYS TYR TYR HIS LYS SER [C terminal]
Click to
show/ hide the primary structure as a list of beta chain residues:
[N terminal] SER LYS GLU PRO LEU ARG PRO ARG CYS ARG PRO ILE ASN ALA THR LEU ALA VAL GLU LYS GLU GLY CYS PRO VAL CYS ILE THR VAL ASN THR THR ILE CYS ALA GLY TYR CYS PRO THR MET THR ARG VAL LEU GLN GLY VAL LEU PRO ALA LEU PRO GLN VAL VAL CYS ASN TYR ARG ASP VAL ARG PHE GLU SER ILE ARG LEU PRO GLY CYS PRO ARG GLY VAL ASN PRO VAL VAL SER TYR ALA VAL ALA LEU SER CYS GLN CYS ALA LEU CYS ARG ARG SER THR THR ASP CYS GLY GLY PRO LY ASP HIS PRO LEU THR CYS ASP ASP PRO ARG PHE GLN AS SER SER SER SER LYS ALA PRO PRO PRO SER LEU PRO SER PRO SER ARG LEU PRO GLY PRO SER ASP THR PRO ILE LEU PRO GLN [C terminal]
See more about this protein below.
It all depends on DNA . . .
A polypeptide is formed at a cell's ribosomes in the process of translation and thus the primary structure can be directly related to the sequence of base triplets ('codons') in the mRNA which is derived as a result of the process of transcription from the section of DNA corresponding to a gene. More specifically, in eukaryotes it is obtained from the exon sections of the DNA, the non-coding intron sections of pre-mRNA being 'edited out' to produce the final spliced mRNA.
[Some micro-organisms use nonribosomal peptide synthetase enzymes - independent of RNA - to synthesise peptides, often with unusual chemical structure, and these include a number of antibiotics and other compounds with a variey of uses.]
. . . but it can still be changed
Polypeptide chains can be altered by
post-translational modifications: sections can be cut off at the ends or out of the middle, and groups can be added to individual amino acid residues, mostly to the R groups forming side chains extending out from the main polypeptide chain. These extra groups can be small: e.g. phosphate, hydroxyl, acetate, methyl or amide groups, or larger: e.g. carbohydrate, lipid.
These changes can alter the shape adopted by the polypeptide chain as it folds.
Secondary structure
The backbone of the polypeptide chain consists of 3 repeated atoms:- N - (α-)C - C -.

Each α-C has an R group, which varies. However the most regular feature is that every N has -H (with a slight charge δ+), and every non α-C has =O (with a slight charge δ-) projecting from it. The NH (H bond donor site) and C=O (H bond acceptor site) groups on each amino acid residue point in different directions ('up' and 'down' in these diagrams). Different sections of the polypeptide chain can become aligned so that NH and O=C groups from different residues can face one another, and form hydrogen bonds between them if they are quite close together: about 0.3 nm :
3 � (angstroms).

In fact, sharing of electrons causes a degree of resonance which means that the bonds between each non α-C and N can be considered to some extent equivalent to a double bond, so that the peptide bond section can be considered to be planar i.e. flat. The other bonds involving α-C are single and allow more rotation.
Hydrogen bonds are responsible for spontaneous re-arrangement of the polypeptide chain into fairly regular sections, with a distinctive 3-dimensional shape, usually coiling into a helix or aligning itself into fairly flat sheets.
The alpha-helix
Sections of the polypeptide chain may coil into an alpha-helix, so that each C=O interacts with H-N on another amino acid 4 residues further along the polypeptide chain. This electrostatic attraction stabilises the polypeptide form in this coiled shape. In other words it would take energy to break this attraction, to unwind it and change it into another shape.



These diagrams show a section of alpha helix with hydrogen bonds (cyan, dotted) between C=O and N-H on different amino acid residues, R groups reduced to simple stubs.
On the left: just the shape of the polypeptide backbone.
In the middle, molecular detail of polypeptide backbone shown.
On the right: elements identified with letters, outside edge of helix coloured.
The alpha helix is described as a right hand helix, with 3.6 amino acid residues per turn. The pitch of the helix is 0.54nm (5.4 Å) . So 36 amino acids would make a helix with 10 loops, 5.4nm (54 Å ) long.
Its diameter is about 1.2 nm (12�)
R groups extend out sideways. Large R groups may limit the continuation of the helix, and proline wll put a kink in it.
Other helical forms are sometimes found. For example, collagen fibrils consist of a left-handed triple helix.
The beta-pleated sheet
If the polypeptide chain does not have bulky R groups, it can interact with another section of polypeptide chain without coiling up. If the polypeptide chain sections are running in the same direction
(
parallel) or in opposite directions
(
antiparallel) then hydrogen bonds can be formed between each C=O and NH. The relative rigidity of the peptide bond section means that polypeptide chains form fairly flat sheets alongside one another, but there is an angle between each layer as other bonds allow more rotation.

Tertiary structure
The polypeptide chain undergoes further twisting and folding, without alterations to the primary and secondary structure described above.
This arrangement is mostly due to attractive forces between the R-groups projecting from the polypeptide backbone, and effectively results in a stabilised, low-energy state. It is sometimes assisted by other - 'chaperone' - proteins (chaperonins) which use energy from ATP to achieve the folding.
- Hydrophobic side chains orientate themselves towards the inside, hydrophilic side chains towards the outside, of most globular protein molecules.
- Hydrogen bonding can occur between R-groups, if they are suitably close.
- Similarly, salt bridges can form between acidic and basic side groups.
- In some cases, disulphide bonds form between pairs of cysteine residues. Being covalent, these provide greatest stability.
In many cases, reaching the tertiary level of protein structure is the final modification of the polypeptide chain and the resulting protein molecule now has a distinctive shape which enables it to function.
However it is worth noting that abnormal protein production is seen in a number of
protein aggregation diseases such as the prion diseases bovine spongiform encephalopathy (BSE) and its associated Creutzfeldt-Jakob disease (CJD). Alzheimer's Disease is characterised by abnormal amounts of malformed protein
('amyloid plaques'), and fibres ('tau tangles') in the brain, and other conditions are associated with accumulation of odd proteins.
Quaternary structure
Some proteins consist of a combination of polypeptide chains with the structure described above.
Expressions such as dimer, trimer, tetramer .. describe the total number (2,3,4 ..) of polypeptide sub-units, and homo- or hetero- signify that each is the same or different. For example the enzyme alkaline phosphatase with 2 identical sub-units is said to be homodimeric and so is glucose-6-phosphate isomerase, whereas haemoglobin, which has 2 α and 2 β chains, is heterotetrameric.
These sub-units are held together by a variety of bonds which are often non-covalent e.g. hydrogen bonds, salt bridges etc, but occasionally covalent - disulphide bonds.
Human Chorionic Gonadotrophin
 Primary structure: Colour by amino acids
Secondary structure: Show as cartoon
Primary structure: Colour by amino acids
Secondary structure: Show as cartoon ...
main chain H bonds
Tertiary structure: Show cysteines, disulphide bonds and sidechain H bonds
Quaternary structure: Show two polypeptide chains
Reset to simple wireframe, coloured by element
These images are taken from the interactive jsmol file HCG on this site.
Protein denaturation
The structure of proteins as described above can be disrupted by a number of factors: heat, variations of pH and salt concentration.
Heat causes increased vibrations within molecules and this neutralises the weak attractive forces responsible for the higher levels of protein structure: hydrogen bonds, salt bridges etc so the molecular folding is reversed. A denatured protein generally lacks some of the properties of the original form: enzymes lose their catalytic capability when their active site becomes altered, and 'egg white' (the protein ovalbumin) changes from transparent and fluid to white and firm when heated. A similar process occurs when eggs are pickled in vinegar (ethanoic acid). Eggs may also be preserved in lime (alkaline solution), and in salt. In these cases decay is prevented because bacterial enzymes are also denatured.
Moderate heating does not affect peptide bonds or disulphide bridges, so the primary structure is unaffected. Enzymes produced by thermophilic organisms contain a higher proportion of amino acids residues with a polar sidechain.
The denaturation process is usually irreversible.
However, under some circumstances denaturation can be prevented by 'heat shock proteins' which are similar to chaperonins mentioned above.

 Home
Home